参考:https://blog.csdn.net/Snoopy_Yuan/article/details/64131129
完整代码:https://github.com/happybear1234/The-Watermelon-book-exercises/blob/master/Practical_3.4/code/Practical_3.4.py
习题3.4 选择两个UCI数据集,比较10折交叉验证法和留一法所估计出的对率回归的错误率
这里从UCI分别选择了数据集Iris Data Set 和 Blood Transfusion Service Center Data Set;通过sklearn库实现,seaborns进行可视化,另外seaborns自带iris的数据集,可以直接拿来用
载入数据,预处理
1
2
3
4
5
6
7
8
9
10
11
12
| import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
iris = sns.load_dataset('iris') # 在线载入自带的 iris 数据集
X = iris.values[:, 0 : 4]
y = iris.values[:, 4]
sns.set(style='white') # 风格设置
g = sns.pairplot(iris, hue='species', markers=['o', 's', 'D']) # 变量关系组图
plt.show()
|
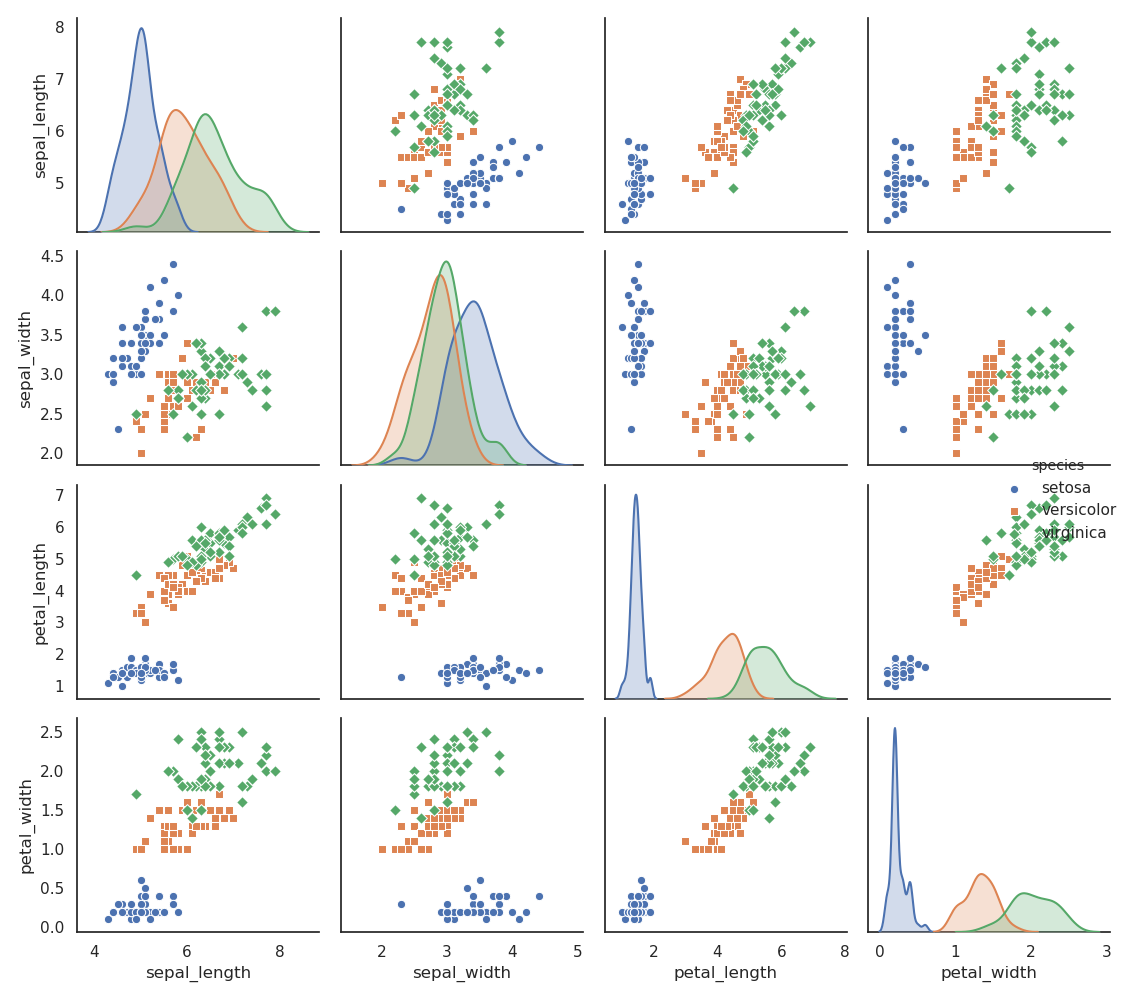
可以看到iris数据类间比较分散,也是后面测试结果比较好的原因之一
sklearn库
1
2
3
4
5
6
| from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn import model_selection
log_model = LogisticRegression(max_iter=1000) # 增加最大迭代次数,也可以减少数据量
m, n = np.shape(X)
|
十折交叉训练
model_selection.cross_val_predict 指定模型直接就返回测试结果
1
2
3
4
5
| y_pred_10_fold = model_selection.cross_val_predict(log_model, X, y, cv=10)
# 打印精度
accuracy_10_fold = metrics.accuracy_score(y, y_pred_10_fold)
print('The accuracy of 10-fold cross-validation:', accuracy_10_fold)
|
The accuracy of 10-fold cross-validation: 0.9733333333333334
留一法
留一法相当于k折交叉训练中,把k取为所有的样例数m,因此要经过m次训练,用循环来实现
1
2
3
4
5
6
7
8
9
10
| accuracy_LOO = 0
# 计算 m 次测试的结果
for train_index, test_index in model_selection.LeaveOneOut().split(X):
X_train, X_test = X[train_index], X[test_index] # 训练集样本,测试集样本
y_train, y_test = y[train_index], y[test_index] # 训练集标签, 测试集标签
log_model.fit(X_train, y_train) # 训练模型
y_pred_LOO = log_model.predict(X_test) # 测试
if y_pred_LOO == y_test:
accuracy_LOO += 1
print('The accuracy of Leave-One-Out:', accuracy_LOO / m)
|
The accuracy of Leave-One-Out: 0.9666666666666667
对于iris数据集,精度比较高,相应错误率较低
类似的,对Transfusion数据集可视化:
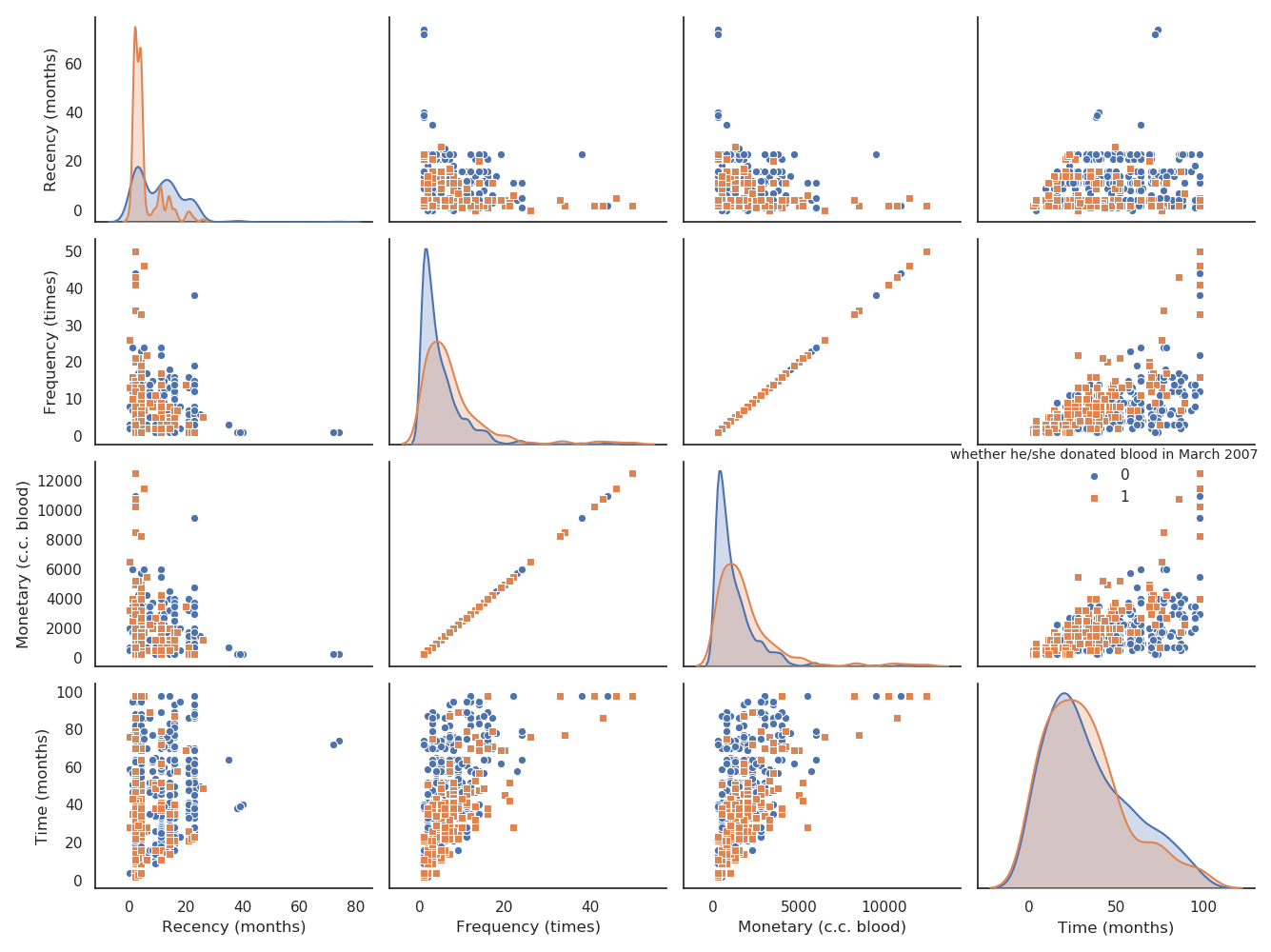
类间分散比较紧凑
相应精度:
The accuracy of 10-fold cross-validation: 0.7687165775401069
The accuracy of Leave-One-Out: 0.7700534759358288
通过以上对比,十折交叉验证法与留一法精度相差不大;而且通过实验,留一法代码跑的时间更长,对于数据越大,这种现象越明显.
因此往后,选择十折交叉验证即可满足精度要求,也节约运行成本